
Architecture for Conway's Game of Life on an FPGA
/It's finally time to talk architecture! This is a continuation of my Conway's Game of Life Adventure, continued from the VGA chat.
Requirements
Before we can start we need to talk about requirements. Let us first define the rules of the Game of Life, copied from Wikipedia.
- Any live cell with fewer than two live neighbours dies, as if caused by underpopulation.
- Any live cell with two or three live neighbours lives on to the next generation.
- Any live cell with more than three live neighbours dies, as if by overpopulation.
- Any dead cell with exactly three live neighbours becomes a live cell, as if by reproduction.
Right up front we know we need to know the status of 9 cells, the cell we are interested in, plus the 8 around it, to find the next state of that cell.
In the lab document that Conway's Game of Life was chosen from, the problem was described as having to be run on an 8x8 LED Matrix. But if you've read my project decision posts, you know I have rather lofty goals. I want to run this game at full standard VGA resolution of 640x480. I also very much would like to run the game at 60 in-game "ticks" per second to match the screen refresh of 60Hz.
The primary limitation I am placing on myself is that I want all of this to happen on my Basys 3 board, using a Xilinx Artix-7-A35, which only has 1800kb of block ram. The assignment presumes you will be using the Terasic DE1-SoC that we were assigned at the beginning of the term, which is has roughly 4 times as much available logic.
Dead Ends
Looking back at our previous two projects, we had to make a stripped down version of tug of war, where we used the strip of LEDs on our dev boards, and you would have two people press buttons and the LED that was lit up would move around. We were told to implement this using a module for every light, and have all the modules be wired together. This method just won't work for the Game of Life based on the requirements I have laid out above. Even if each module only used part of one logic slice, I've only got 5k logic slices and 302k cells I want to model.
The First Step
Rather than use a separate module for each "cell" in my game, which is the massively parallel option, I realized the only way for me to get this working on my Basys 3 was to use block rams to store the current and next state. A 1 bit wide and 307k address long block ram, built out of cascaded 32k block rams was the answer. Though I didn't end up only using 307k addresses, making the addressing scheme easier by using X and Y coordinates concatenated together lead to needing 19 bits of addressing and 524k addresses. This means each ram we use will require 16 of the 50 available block rams on the board.
Two Naive Approaches
The first approach I attempted was extremely naive. I figured if I need to read 9 cells to calculate the next state for 1, I would just infer 9 read ports on my ram. I justified this in the short term in my head by the fact that we would be using so many cascaded block rams and each one has 2 read ports, I figured it might work. Well when I tried to implement the design it attempted to use distributed memory and very quickly ran out of available logic slices, which meant my attempted 9 read port cascaded block ram wasn't a viable option. You live and you learn I guess.
We know we need to read 9 cells status in order to determine the next state of any given cell. So my next idea was to run the clock for the overall design at 9 times the speed of the pixel clock for the VGA, or 225MHz. This would allow us to read 9 addresses in the time it would take the output to draw one pixel, allowing us to keep pace with the drawing of pixels when we are calculating the next state of the pixels. It would later turn out that at least 10 clock cycles would be required, but it would end up not mattering anyways. The problems here arose when just testing out the VGA driver displaying a random set of data loaded into the block ram. When running the block ram at 225MHz, the design would fail timing. This is my first time running into a situation like this, but I think it has something to do with the fact that the block rams are spread out all over the FPGA, what with 16 of them being all cascaded together. The spread out nature of the cascaded block rams combined with the high operating frequency led to the timing failure.
Through continued experimentation I discovered that the highest integer multiple of 25MHz I could run the block ram at in this configuration was 150MHz. This means I needed to get more creative, the brute force approach of reading 9 cells for every cell just wasn't going to work, especially if I wanted to run the game at 60 in game "ticks" per second.
The Architectural Revelation
This wasn't a last minute revelation, I was just hoping to make the game logic simpler in exchange for making the it less efficient, but it would seem that wasn't meant to be. We know we need to read 9 cells in order to compute the next state of each cell, but as long as we compute the next states in a reasonable manner we can avoid having to read most of the cells for most of the next states being calculated. What I mean is that if we design our game logic to raster across the board in the same fashion as the VGA output will be doing, we can see that 6 of the cells for calculating the next state of the next cell are the same from the previous cell. This means we only need to read 9 cells, once, at the beginning of the row, and then for each consecutive cell in that row we can shift the previously read cells over and read in 3 new ones to do our next state calculation.
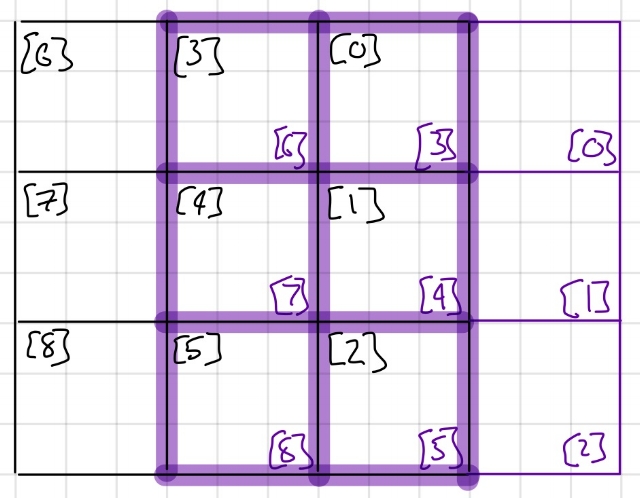
Above, you can see an example of how the shifting of the cells will work. In black I have denoted the grid of 9 cells being read, with the status of the cells being loaded into a 9 bit long register. When you shift to calculate the next cell, denoted in purple, because of the way I have arranged which cells go to which bit in the register, we can just shift the bits 3 times to the left and then load in the 3 cells we need.
Data Flow
The first plan I had for the data flow model of the design was to use just two block rams, one for the present state and one for the next state. The game logic would use one as the present state, writing out to the other as the next state, and then would switch for the next frame, reading from what was previously the next state and writing to what used to be the present state. I would also have had the VGA Driver read from whichever was currently the present state. This plan had a lot of extra complexity, but would most efficiently utilize the resources on our board.
Knowing that our Artix-7-a35 has 50 available block rams and that each of the rams in our design will use 16 of them, we have space for 3 rams in the design. This is when I decided I would use a dedicated ram just for the video frame buffer, this way the VGA Driver will always be reading from the same ram. My original idea in this configuration was still to have the game logic switch back and forth, reading from one and writing to the other ram. It would also be writing to the frame buffer every time as well.
This is when I realized another potential problem with the design. If I were going to write to the VGA ram, the game logic would not be able to go faster than the display output, or it would end up over writing data for a given frame that had not been displayed yet. Sure I could have come up with some sort of control signal to tell the game logic when a row had finished being displayed so it could write over it, and then wait for the next control signal. A new idea came to mind though when I "saw" all of the extra rows at the bottom of the screen that are not being displayed. Could I copy all the contents from the next state ram into the present state and frame buffer rams after the next state was calculated but before the next frame needed to be drawn?
The Architectural Promised Land
Doing some back of the envelope math we can see that our goal of copying the contents of the next state ram into the present state and the VGA rams. At 150MHz, our clock period is 6.67ns. We will need 3x639 + 9 clock periods per row, times 480 rows, means the game logic will take roughly 6ms to complete. We will also need 307k clock cycles to transfer the data, which is roughly 2ms. Our budget for each frame is 1/60th of a second, or 16.67ms, which means we have plenty of time to get the logic and the transfer done before the next frame starts. This method decreases the efficiency of the design, but it also decreases the complexity of the reading/writing structure, as well as giving me the opportunity to write another module, to copy the data.
The game logic can start at the beginning of when the frame is being drawn, but we need to be careful about the copying logic. The copying logic wont actually fit into just the period during the extra rows at the bottom of the frame, it would take too long. We can however, start the copy process before the last row of the frame has been drawn, we just have to ensure we don't start too early, overwriting any rows that have not been displayed yet.
Conclusion
We started with a rather naive and brute force approach to this design, which luckily didn't end up working. This forced us to use our heads and come up with a better way to access the data we needed. I believe something close to the reverse happened when it comes to the data flow of the overall design though. We started with a rather complex reading and writing idea, only to realize we did not need all that extra complexity.
Unfortunately, architecting the design isn't the last step, it has to be implemented in SystemVerilog. My first attempt at this did not go well, which you can see in the youtube video below.
It would seem I made a great deal of what I would call off by one errors throughout my design. Whether they are in the game logic, or in the transfer logic, the cells are being shifted to the right and down. You can see some of the little flyers in there though, so it would seem that at its core the game logic is working.
Next time we can go into what I did to figure out what was wrong, and how I fixed it.